Als ich vor Jahren mein Startup leitete, war ich nebenbei Qualitätsmanagementbeauftragter. Ich habe ISO 9001-Audits durchgeführt, Prozessbeschreibungen geschrieben, PDCA-Kreisläufe durchlaufen. Damals fand ich das teilweise lästig. Teilweise cool, weil es in der Firma Prozesse erzwang – und jeder wusste, dass selbst wenn man Jan überredete, es die ISO9001 trotzdem geben würde 🤣. Heute bin ich dankbar dafür.
Denn als ich anfing, ernsthaft mit KI-Assistenten zu programmieren, stellte ich schnell fest: Die Technik ist beeindruckend, aber ohne Struktur verpufft sie. Claude Code kann brillanten Code schreiben – aber nur, wenn es versteht, was das Projekt ist, wie es aufgebaut ist und was erwartet wird.
Das ist im Grunde das gleiche Problem, das jedes Unternehmen kennt: Ein neuer Mitarbeiter kann noch so gut sein – ohne vernünftige Einarbeitung steht er erstmal im Dunkeln.
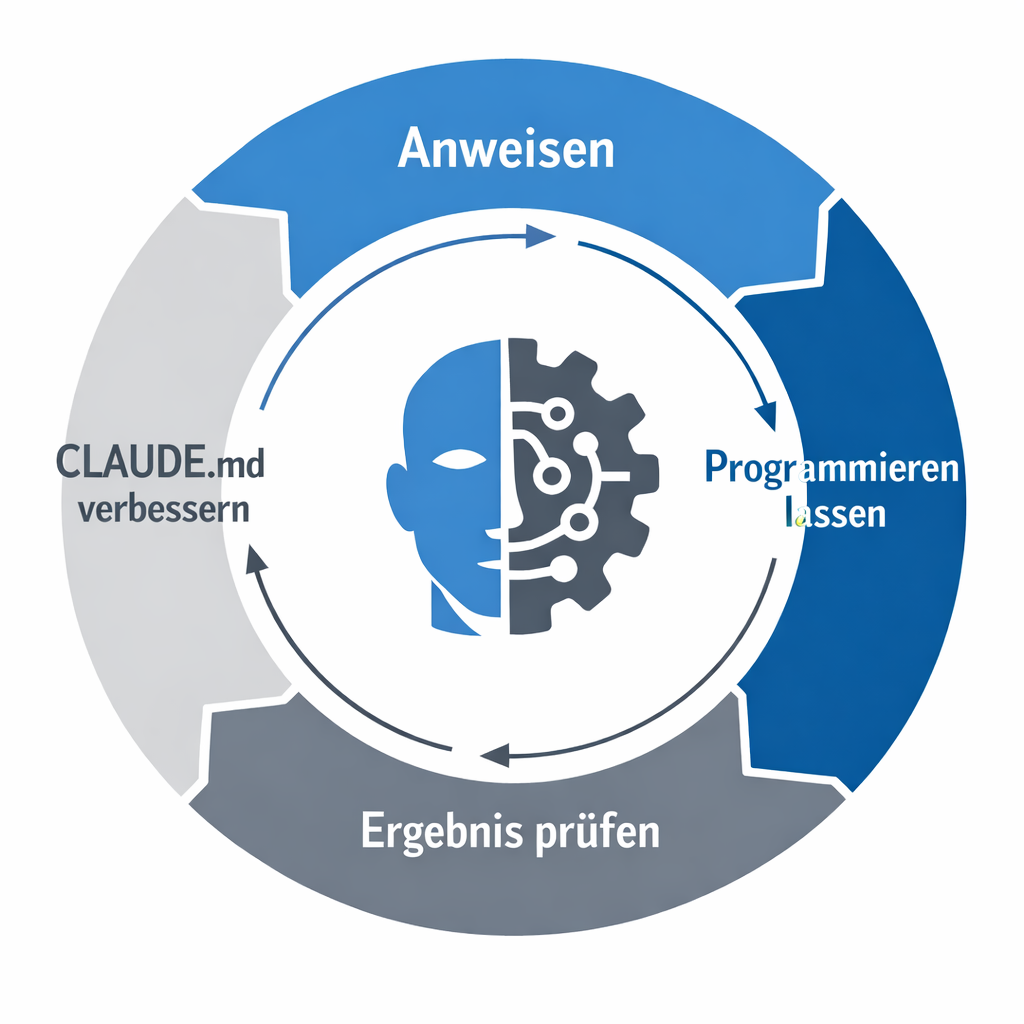
Zwei Dokumentationsebenen: Eine für Menschen, eine für Maschinen
In meinen Kundenprojekten habe ich begonnen, konsequent zwei Markdown-Dateien zu pflegen.
Die README.md ist das, was man kennt: eine Kurzeinführung für Menschen. Was ist das Projekt? Wozu dient es? Wie startet man es? Das Übliche – aber konsequent aktuell gehalten.
Daneben steht die CLAUDE.md. Diese Datei ist speziell für den KI-Assistenten geschrieben. Sie enthält die Grundstruktur des Projekts, erklärt wie Dinge aufgebaut sind, wie sie zusammenhängen, wo die Fallstricke liegen. Claude Code liest diese Datei automatisch beim Start einer Session.
Der Clou: Claude schreibt diese Datei im Wesentlichen selbst. Ich lasse die KI nach einer Arbeitssession ihre Erkenntnisse dokumentieren. Was hat sie gelernt? Wo gab es Probleme? Was muss die nächste Instanz wissen? Ich korrigiere dann Kleinigkeiten, aber der Großteil kommt von der KI selbst.
Das klingt nach einer Spielerei. Ist es nicht. Es ist eine Wissensdatenbank, die mit jedem Arbeitszyklus besser wird.
ISO 9001-Denkweise auf KI-Arbeit übertragen
Hier kommt mein QM-Hintergrund ins Spiel. Im ISO 9001-Kontext gibt es ein Grundprinzip: Wenn ein Prozess regelmäßig Probleme verursacht, beschreibt man ihn besser. Man wartet nicht, bis jemand den gleichen Fehler zum dritten Mal macht – man schreibt auf, wie es richtig geht 👌.
Genau das mache ich mit Claude. Wenn ich beobachte, dass die KI sich regelmäßig an bestimmten Problemen aufhält – etwa an einer ungewöhnlichen Build-Konfiguration oder einer Projektkonvention, die nicht offensichtlich ist –, fordere ich sie auf, das in der CLAUDE.md festzuschreiben. Damit die nächste Instanz diesen Fehler nicht wiederholt.
Wenn die Beschreibungen dabei zu kompliziert oder verworren werden, lasse ich Claude sie vereinfachen. Die Anweisung lautet dann sinngemäß: „Schreib das so um, dass deine nächste Instanz es auf Anhieb versteht.” Das ist nichts anderes als der PDCA-Kreislauf: Planen, Durchführen, Überprüfen, Verbessern. Nur eben für eine KI statt für ein Team.
Das Ergebnis sind Prozessbeschreibungen, die immer besser werden. Nicht weil ich sie mühsam pflege, sondern weil die kontinuierliche Verbesserung in den Arbeitsablauf eingebaut ist.
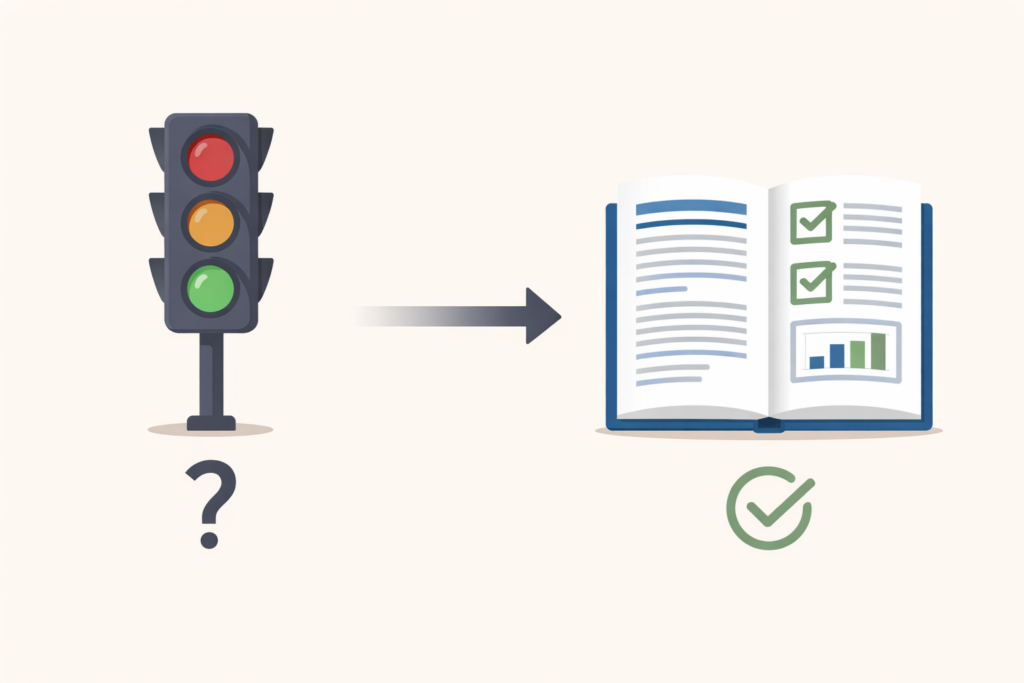
Warum „Tests sind grün” nicht reicht
Wenn eine KI programmiert, braucht man Tests. Das ist unstrittig. Was weniger offensichtlich ist: Die klassische grün/rot-Anzeige reicht nicht.
Mir war von Anfang an wichtig, dass meine Tests einen textuellen Report erzeugen. Nicht nur „bestanden” oder „fehlgeschlagen”, sondern: „Teste jetzt die Filterberechnung mit Parametersatz A. Habe validiert, dass der Ausgabewert innerhalb der Toleranz von 0,1% liegt. Prüfe nun die Grenzwerte für B, C und D.”
Warum? Weil ich wie ein Chef handele, der Validierungen hinterfragt 🙈. Wenn ich in einem Testergebnis sehe, dass Claude etwas geprüft hat, stelle ich Fragen: „Hast du wirklich den Originalwert verglichen oder nur gegen deinen eigenen Output getestet?” Manchmal macht sich die KI Dinge einfacher als gewollt 😮. Das fällt nur auf, wenn man versteht, was geprüft wurde.
Zusätzlich zum lesbaren Report erzeuge ich einen JSON-Output. Der ist für die maschinelle Auswertung gedacht – Continuous Integration, automatische Dashboards, Trendanalysen. Aber er ist auch für die KI selbst nützlich: In der nächsten Session kann Claude die JSON-Reports lesen und weiß sofort, was beim letzten Mal funktioniert hat und was nicht.
Diese Doppelstruktur – menschenlesbar und maschinenlesbar – ist mehr Aufwand beim Einrichten. Aber sie zahlt sich aus, weil sie Qualität absicherbar macht. Nicht nur „grün” 😉.
Strukturen beschreiben lassen
Es gibt ein Prinzip, das ich mittlerweile auf alles anwende: Jede Struktur, die ich aufbaue, lasse ich von Claude beschreiben.
Wenn ich eine neue Teststruktur einrichte – sei es als CTest in CMake-Projekten oder als zentral aufgerufenes Python-Skript –, dann dokumentiert Claude, wie diese Struktur funktioniert, wo sie liegt, wie man sie aufruft. Das wird Teil der CLAUDE.md.
Der doppelte Nutzen: Erstens kann die nächste KI-Instanz sich sofort einarbeiten und die eigene Arbeit verifizieren. Zweitens kann ich selbst nach drei bis sechs Monaten Pause in ein Projekt zurückkehren und weiß sofort, was Sache ist.
Diesen zweiten Punkt unterschätzen viele. Wer als Einzelentwickler oder in einem kleinen Team arbeitet, kennt das Gefühl: Man öffnet ein Projekt nach einem halben Jahr und braucht einen Tag, um sich wieder reinzudenken. Mit einer guten CLAUDE.md brauche ich eine halbe Stunde – weil dort steht, was ich damals wusste. Und die KI es sowieso eher “nach 5sec” alles wieder kennt 🤣.
Der Standard über alle Projekte
Über die letzten Monate hat sich bei mir ein Standard etabliert, den ich inzwischen auf alle Kundenprojekte anwende:
Erstens ist jedes Projekt „KI-wartbar”. Das bedeutet: Eine neue KI-Instanz kann sich in das Projekt einarbeiten und produktiv werden, ohne dass ich eine Stunde Kontext liefern muss.
Zweitens existiert eine CLAUDE.md, die nicht einmalig geschrieben, sondern aus Session-Learnings gewachsen ist. Sie ist ein lebendiges Dokument.
Drittens gibt es eine Teststruktur mit textuellem und JSON-Output. Der Mensch kann die Ergebnisse überfliegen und versteht, was geprüft wurde. Die Maschine kann sie auswerten.
Viertens gibt es einen einfachen Einstiegspunkt. Tests aufrufen, Ergebnisse lesen, weiterarbeiten. Kein Setup-Marathon.
Das klingt nach viel? Ist es anfangs auch. Man muss diese Strukturen aufbauen – und ja, man muss sie betreuen. Aber wenn sie einmal stehen, wird etwas Bemerkenswertes möglich: Man wird hemmungslos.
Wenn Tests da sind und eine KI die Arbeit macht, traut man sich an Dinge heran, die man als einzelner Entwickler nie angefasst hätte. Umstrukturierungen, die eigentlich funktionierenden Code betreffen. Aufräumarbeiten, die man seit Jahren vor sich herschiebt. Die Qualität wurde dabei in meinen Projekten teilweise erheblich besser – nicht trotz der KI, sondern weil die Strukturen ihr den Rahmen geben, in dem sie ihre Stärken ausspielen kann.

Kein Babysitten, sondern Einarbeitung
Man merkt an allem, was ich beschreibe: Das ist nicht so, dass man eine KI loslaufen lässt und am Ende fertigen Code einsammelt. Man muss Strukturen betreuen, Ergebnisse prüfen, Prozesse verbessern.
Negativ formuliert könnte man das „Babysitten” nennen. Ich formuliere es lieber so: Man arbeitet einen sehr guten, aber manchmal zerstreuten Mitarbeiter ein. Und man baut dabei Strukturen auf, die nicht nur der KI helfen, sondern dem gesamten Projekt 😁.
Das Ergebnis war für mich: hochqualitative Strukturen, die vorher nicht existierten. Projekte, die nicht nur funktionieren, sondern wartbar, testbar und nachvollziehbar sind. Für die KI – und für jeden Menschen, der nach mir kommt.
Dies ist Teil 2 einer dreiteiligen Serie über KI-gestützte Softwareentwicklung in der Praxis. In Teil 3 geht es um die praktische Implementierung: Wie REST-Schnittstellen, Selbstdiagnose-Patterns und MCP-Integration die Brücke zwischen KI und laufender Software schlagen.