Ausgangslage
Ich leite ein kleines Ingenieurbüro. Wir machen IoT, Maschinenanbindung, Software-Entwicklung. Fünf Leute, keine IT-Abteilung. Die IT-Abteilung bin ich, abends und am Wochenende.
Unser VPS bei Strato lief seit sieben Jahren. Docker-Container über Container, Start-Skripte aus verschiedenen Epochen, ein Backup-Konzept, das man wohlwollend als „gewachsen“ bezeichnen konnte. Manches lief noch, manches war seit Jahren gestoppt und lag einfach nur noch rum. Der Server funktionierte, aber wenn mich jemand gefragt hätte, was da eigentlich alles drauf ist — ich hätte raten müssen.
Der Umzug auf einen neuen VPS stand seit Monaten an. Bessere Hardware, aktuelleres Ubuntu, die Gelegenheit, mal auszumisten. Aber ein Serverumzug mit dutzenden Docker-Containern, VPN, Backups, Sicherheitskonfiguration — das ist ein Wochenende Arbeit. Mindestens. Und ich hatte dieses Wochenende seit Monaten nicht.

SSH-Zugang und „Arbeite dich ein“
Ich nutze Claude Code seit einiger Zeit für Softwareentwicklung. Irgendwann kam der Gedanke: Wenn das Ding per Terminal arbeitet und mein SSH-Key auf dem Server liegt — warum soll es nicht auch Serveradministration können?
Der Anfang war simpel: Neuen VPS bestellt, Claude den SSH-Key auf den neuen Server kopieren lassen. Ab diesem Moment hatte die KI denselben Zugang wie ein Systemadministrator. Per SSH, mit Root-Rechten.
Aber ich habe nicht mit „migriere alles“ angefangen. Der erste Auftrag war: „Arbeite dich auf dem alten Server ein.“
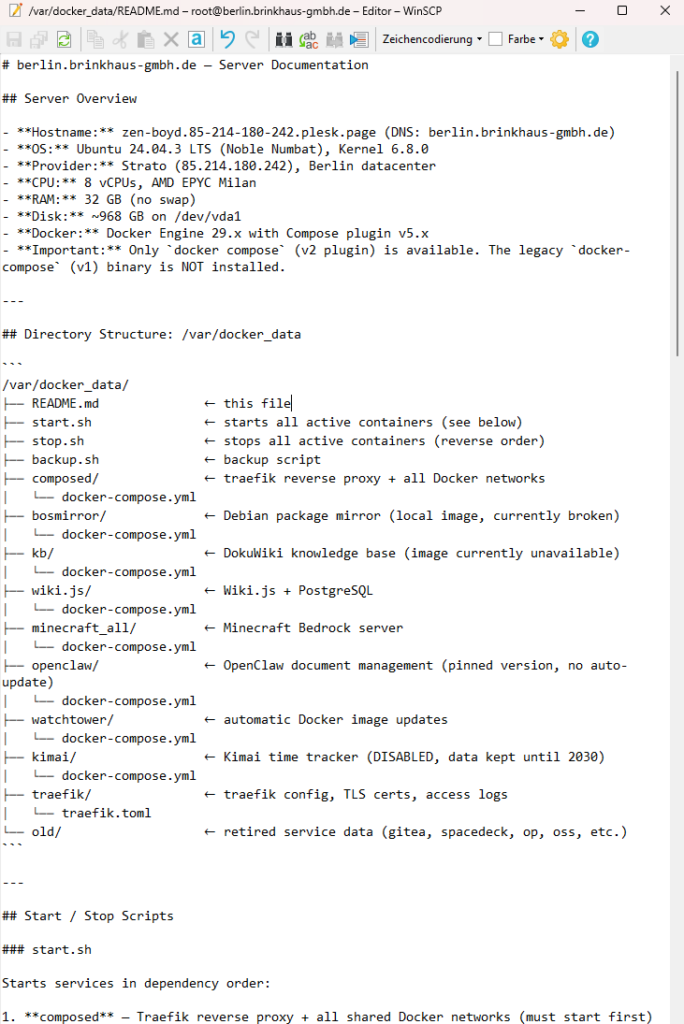
Claude sollte die Struktur unter `/var/dockerdata` analysieren. Jedes Verzeichnis durchgehen, herausfinden, welche Container noch aktiv sind, wie sie gestartet werden, welche Daten wo liegen. Die Backup-Skripte lesen und verstehen.
Das Ergebnis war eine Dokumentation, die ich selbst nie geschrieben hätte. Nicht aus Faulheit — sondern weil man als Betreiber eines Servers vieles im Kopf hat und es nie aufschreibt. Claude hatte keinen Kopf, in dem etwas implizit vorhanden war. Also schrieb es alles auf.
Diese Dokumentation landete als README.md direkt in `/var/dockerdata`, neben der Infrastruktur selbst. Kein externes Wiki, kein separates Repo. Die Doku dort, wo die Sachen sind.
Aufräumen, dann umziehen
Vor dem Umzug kam das Ausmisten. Container, die seit Jahren nicht mehr liefen — Gitea, Spacedeck, ein alter Build-Slave, ein aufgegebenes Monitoring — wurden nicht gelöscht, sondern mitsamt ihrer Daten nach `/old` verschoben. Raus aus der aktiven Struktur, aber wiederherstellbar. Das war mir lieber als endgültiges Löschen.
Das lief iterativ. Claude schlug eine Struktur vor, mir gefiel nicht alles, ich korrigierte, Claude passte an. Normaler Arbeitsprozess, wie mit einem Mitarbeiter.
Neuer Server: Zielbild statt Schritt-für-Schritt
Auf dem neuen Server habe ich Claude nicht Schritt für Schritt angewiesen, sondern ein Zielbild beschrieben:
- Zentrale Ablage unter `/var/docker_data` für alle Container
- VPN-Verbindung zur Fritzbox in der Firma
- Nächtliche Backups zum Firmenserver über das VPN
- Brute-Force-Schutz
- Automatische Updates für Docker-Images und OS-Pakete
- Laufende Dokumentation im selben Verzeichnis
Der letzte Punkt war wichtig. Ich sagte Claude: „Schreib Dir selbst eine Dokumentation. Was ist eingerichtet, was fehlt noch, wie ist der Stand.“ Das hatte einen praktischen Grund: Ein Serverumzug an einem Stück ist für einen Geschäftsführer unrealistisch. Es kommen Anrufe, Mails, Kundentermine dazwischen. Wenn ich nach drei Stunden Pause weitermachte, las Claude seine eigene Dokumentation und wusste, wo wir standen.
Nebenbei konnte ich Wartezeiten nutzen. Während der Datentransfer vom alten Server lief — Gigabytes über die Leitung — besprachen wir die VPN-Strategie oder das Update-Konzept.
Was Diskussion brauchte und was nicht
Eine Sache, die gut funktionierte: Claude unterschied von sich aus, was meine Meinung erfordert und was nicht.
Das VPN war ein echtes Diskussionsthema. WireGuard, IPSec, OpenVPN — jeder Ansatz hat andere Implikationen, abhängig von der Fritzbox-Konfiguration. Claude legte Optionen vor, erklärte Vor- und Nachteile, und wir entschieden gemeinsam für strongSwan mit IKEv1 (das, was die Fritzbox am zuverlässigsten kann).
SSH-Härtung hingegen war kein Diskussionsthema. Fail2ban installieren, Passwort-Login deaktivieren, Key-Only-Auth erzwingen — das sind Best Practices, keine strategischen Entscheidungen. Claude richtete das ein und meldete das Ergebnis. Fertig, weiter.
Wo es schiefging: das Backup
Nicht alles lief glatt, und das gehört in einen ehrlichen Bericht.
Das Backup richtete Claude zunächst mit rsnapshot ein — ein bewährtes Tool, das inkrementelle Backups über Hardlinks macht. Die Sicherung lief nächtlich per Cronjob über das VPN auf den Firmenserver, montiert per CIFS.
Zwei Tage lang sah alles gut aus. Dann bat ich Claude, zu verifizieren, ob wirklich alle Dateien korrekt gesichert werden. Ergebnis: Symbolische Links wurden über CIFS nicht korrekt übertragen. Bei Docker-Containern, deren Verzeichnisstrukturen auf Symlinks angewiesen sind, ein echtes Problem.
Das war kein Fehler, den Claude hätte vermeiden müssen — rsnapshot über CIFS ist eine valide Konfiguration, und dass Symlinks über SMB-Mounts Probleme machen, ist eine jener Eigenheiten, die man kennt oder eben nicht. Aber es zeigt: Man muss die Ergebnisse prüfen. KI-Arbeit ist nicht fehlerfrei, und Vertrauen ohne Kontrolle wäre fahrlässig.
Nach Beratung mit Claude sind wir auf Restic umgestiegen. Restic überträgt die Daten als deduplizierte, verschlüsselte Blöcke — das Dateisystem des Ziels spielt keine Rolle mehr. Symlinks, Berechtigungen, Hardlinks werden korrekt erfasst. Das Backup läuft seitdem sauber.
Hätte ich das Problem ohne KI schneller gefunden? Vielleicht. Hätte ich es ohne die systematische Verifikation überhaupt gefunden, bevor es im Ernstfall zu spät gewesen wäre? Vermutlich nicht.
Das Ergebnis
Der Umzug dauerte, verteilt über mehrere Sessions, etwa zwei Nachmittage meiner Zeit. Die Hälfte davon war Diskussion und Entscheidungsfindung, nicht Handarbeit.
Am Ende steht ein Server mit:
- Traefik als Reverse Proxy mit automatischen Let’s-Encrypt-Zertifikaten
- Wiki.js, OpenClaw (Dokumentenmanagement), Minecraft-Server für die Kinder, Watchtower für automatische Image-Updates
- VPN per strongSwan/IPSec zur Firmenzentrale, darüber CIFS-Mounts zu zwei Synology-NAS
- Nächtliche Restic-Backups auf den Firmenserver
- fail2ban, SSH-Härtung, unattended-upgrades
- Einer README.md, die den kompletten Zustand beschreibt
Nicht perfekt: Der alte DokuWiki-Container basiert auf einem Image, das Docker Hub inzwischen entfernt hat. Ein Debian-Mirror-Container hat ein lokales Image, das nach der Migration nicht geladen wurde. Das steht in der Dokumentation unter „Known Issues“ — auch das hat Claude selbst geschrieben. Offene Probleme zu dokumentieren statt sie zu verstecken, hat mir gefallen.
Dokumentation als Nebenprodukt
Der Punkt, der mich rückblickend am meisten beschäftigt: die Dokumentation.
Ich habe Server seit über 15 Jahren selbst administriert. Ich hatte nie eine vollständige, aktuelle Dokumentation meiner Infrastruktur. Nicht weil ich es nicht wollte, sondern weil es immer die Aufgabe war, die nach dem nächsten Kundenanruf hinten runterfiel.
Claude dokumentiert nicht nur, weil ich es anweise. Claude dokumentiert, weil ich benötige, dass es den Zustand für seine nächste Session festgehalten hat. Es hat kein implizites Wissen, kein „ich weiß ja, wie ich das damals eingerichtet habe“. Alles, was Claude weiß, steht in Dateien. Die Dokumentation ist keine Tugend — sie ist eine technische Notwendigkeit.
Aber: wenn morgen ein Auditor fragen würde, was auf meinen Servern läuft und wie sie abgesichert sind — ich hätte alle Dokumente sauber abgelegt vorliegen und griffbereit. Das gab es vorher so nicht 👌 .
Was heißt das für IT-Abteilungen?
Ich mache mir Gedanken über IT-Abteilungen in kleinen und mittleren Unternehmen. Nicht, weil KI morgen alle Admins ersetzt — das ist Unsinn. Aber die Art der Arbeit verschiebt sich.
Routine-Administration an Linux-Servern — Pakete aktualisieren, Dienste einrichten, Logs prüfen, Backups konfigurieren — das kann eine KI heute schon brauchbar erledigen. Nicht perfekt, wie das Backup-Beispiel zeigt. Aber brauchbar genug, dass man die Ergebnisse prüfen und korrigieren kann, statt alles selbst zu tippen. Und ehrlichgesagt würden auch IT-Fachkräften bestimmte Fehler passieren und sie wären darauf angewiesen, z.B. zu prüfen, ob ein Backup überhaupt wiederherstellbar ist.
Was man weiterhin braucht: jemanden, der weiß, welche Fragen man stellen muss. Der merkt, dass man Symlinks über CIFS prüfen sollte. Der entscheidet, ob WireGuard oder IPSec die richtige Wahl ist. Architekten statt Handwerker, wenn man so will.
Für ein kleines Unternehmen wie meines ist das eine gute Nachricht. Ich brauche keinen Admin, der regelmäßig vorbeikommt. Ich brauche mein eigenes technisches Verständnis — und ein Werkzeug, das die Ausführung übernimmt.
—
*Jan Brinkhaus leitet die Brinkhaus GmbH in Isernhagen. Das Ingenieurbüro ist spezialisiert auf IoT, Maschinenanbindung und Software-Entwicklung.